Es importante que la calidad de nuestros bugs sea correcta. Es lo justo, lo que nosotros pedimos al producto y al código, que también se aplique en esta definición del bug, para que tengan que preguntarnos lo menos posible y se vaya directo al grano.

Si quieres saber más sobre cómo gestionarlos, en breve haré otro artículo para saber qué pistas te dan y no te estás dando cuenta de ello, ¡nos hablan!
Lo primero que hay que hacer es seleccionar unos cuantos bugs que ya tenemos dados de alta y analizar qué se puede mejorar en ellos. ¿Cómo? Revisando los puntos que aquí comento, y teniendo en cuenta que aunque al principio nos cueste luego será más rápido y lo haremos casi sin darnos cuenta.
En un primer análisis nos daremos cuenta de si nuestros bugs tienen puntos de mejora, porque lo más identificable es saber cuándo algo no nos parece correcto, nos chirría a la vista. ¡Uy, uy, uy!
Puntos de revisión
1.- Comprueba si no existe ya, aún así se nos puede escapar algún duplicado, pero haz una búsqueda rápida por palabras clave y mira lo último introducido por los compañeros, quizá ellos lo detectaron antes. Sin embargo, no tardes mucho en darlo de alta para que no se nos olviden los detalles del mismo.
Lo que suele ocurrir: Creamos bugs similares o duplicados.
2.- Pon un título adecuado, que describa la funcionalidad clara de lo que falla.
Lo que suele ocurrir: Títulos cortos, que no dejan claro el objetivo de la tarea, la esencia.

3.- Descripción completa y focalizada ( lo que no sea relevante molesta ). Incluir datos relevantes, usuario utilizado en la prueba donde vimos el fallo, imágenes, sistema operativo, navegador, URL implicada….
Antes de darlo de alta comprobar que lo podemos reproducir con los pasos indicados al menos 2 veces, si no ocurre siempre, indicarlo también, si es aleatorio.
Lo que suele ocurrir: Descripciones vacías o que dejan mucho que desear, dejando que las personas adivinen qué es lo que tenemos que probar.
Añade por defecto este tipo de plantilla en tu descripción:
· Pasos para reproducir: Indica los pasos claros para reproducir el bug.
· Resultado esperado: Cómo se debería comportar
· Resultado actual: Qué es lo que realmente está haciendo, motivo del bug
Ejemplo:

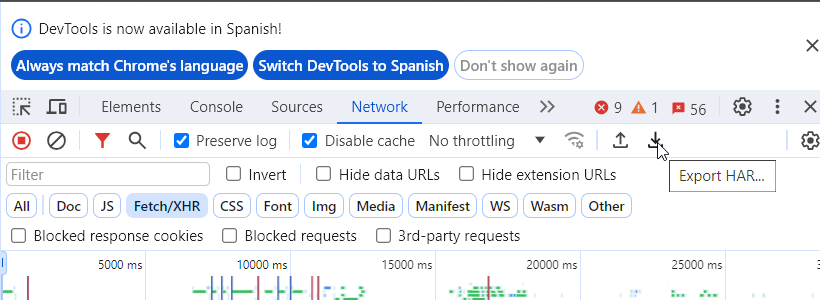
4.- Mensajes de error y Logs: Añadir imagen con el error o con el inspector del navegador donde se vea si da un 500, un 404…. Podemos exportar el .har de las operaciones realizadas mientras estamos con el inspector de operaciones del navegador chrome por ejemplo y luego adjuntarlo para importar y ya ofrecemos la secuencia de llamadas realizadas.
Lo que suele ocurrir: Decimos que aparece un mensaje de error y no ponemos cual y probablemente tenemos el error de back viéndolo desde el inspector pero no pensamos en compartir ya esta información.
5.- Entorno, indicar en qué entorno hemos descubierto el fallo. ¿Puede ser que falle también en producción o en algún otro entorno?
Lo que suele ocurrir: descubrimos que algo falla en un entorno preproductivo y no pensamos que quizá ya haya llegado a producción y en este caso habría que indicarlo, comprobar si en producción ocurre ya.

6.- Prioridad del bug según nuestro criterio, esto es algo que luego puede modificarse por parte del equipo.
· Blocker: no deja hacer las operativas debido a este fallo.
· Critical: Caida de la aplicación o pérdida de datos.
· Major: Pérdida importante en una operativa concreta
· Minor: Pérdida leve en una operativa concreta
· Trivial: Suelen ser aspectos de Interfaz gráfica que no bloquean.
Lo que suele ocurrir: Todos o casi todos los bugs tienen la misma prioridad y es un problema porque es como si no la tuvieran, no nos sirve para saber cuales son los más urgentes de resolver porque causan mayor perjuicio al usuario.

7.- Informador, quien ha dado de alta el bug por si alguien quiere preguntar, si no es posible indicarlo porque el creador del bug es algún sistema automático genérico, indicarlo en los comentarios o en la descripción.
Lo que suele ocurrir: A veces no sabemos quién lo reportó porque se guarda el bug como algo automático con usuario genérico.

8.- Componente o grupo funcional al que afecta. Esto nos ayuda a asignarlo a un bloque concreto y poder afinar luego en las búsquedas también. Pregúntate si funcionalmente que falle en este punto puede provocar que algo más falle, piensa en las relaciones.
Lo que suele ocurrir: bugs sin poder asociar funcionalmente entre ellos, y no podemos filtrar por aquellos referidos al módulo de Ingresos, por ejemplo.

9.- Estado del bug, es importante mantener el estado actualizado para saber en qué punto nos encontramos. El ciclo de vida del bug exige ir modificando su estado para que todo el equipo sepa de su situación. Un típico workflow de bugs suele tener estos estados:
- Nuevo: El bug aún no ha sido revisado.
- Abierto: Cuando ya ha sido revisado y se reconoce que existe la incidencia.
- Asignado: Alguien está asignado para su solución.
- En progreso: La persona asignada ha empezado con los trabajos de resolución. Si no se puede reproducir lo mejor es hablar con el tester adecuado o con quién lo reportó.
- Arreglado: El desarrollador cree que ya está resuelto, pero el bug no se cierra hasta que sea comprobado.
- Cerrado: Cuando ha sido comprobado su arreglo, se cierra el bug.
- Reabierto: Si finalmente con el tiempo se observa que no ha sido resuelto se reabre para volver a revisarlo, el ciclo se repite hasta que quede cerrado.
- Duplicado/Invalido: No serán arreglados porque ya estaba creado o porque realmente no es un bug y se ha visto con posterioridad.
Lo que suele ocurrir: No es mantenido el estado del bug correctamente o no se terminan de cerrar los que ya fueron arreglados. Falta de comentarios sobre lo que va ocurriendo con el propio bug. Suelen quedarse a veces en un mismo estado mucho tiempo sin saber el motivo de ese parón.
10.- Tipo de error, se puede introducir un campo en el bug para luego poder filtrar también por tipo de error que nos permita luego sacar conclusiones sobre qué tipo de errores son los más frecuentes. Tipos posibles: Error de código, Error de diseño, Nueva sugerencia, Error de documentación, Error de Hardware, Error por olvidos en despliegue, Error de análisis. Interesa tenerlos en un desplegable para que siempre se ponga el mismo tipo y no que cada persona escriba una descripción sobre el tipo de error.
Lo que suele ocurrir: tomamos todos los bugs por igual sin diferenciar el tipo de error que es y luego no podemos tomar conclusiones y acciones para evitarlo en el futuro.

11.- Dependencia automáticas. Si ese bug afecta a alguna prueba automática, esa prueba automática fallará en ese punto hasta que se arregle, inhabilitando el resto de pasos de la prueba automática por debajo por lo que en algunos casos interesa indicar esto también para comunicar con los equipos de automáticas y para no bloquear tests y no quitarnos visibilidad.
Lo que suele ocurrir: No se indica si afecta a alguna prueba automática con lo que no se le da la importancia relevante para arreglarlo, es una dependencia más que debería tratarse para no obstaculizar la parte de test automáticos.

12.- Comunica si tienes sospechas de algun motivo de porqué falla, workarounds posibles hasta que esté arreglado, aportar contexto. Todo esto ayudará al equipo.
Lo que suele ocurrir: Quizá sepamos o intuimos el motivo o posible solución hasta que se arregle, pero no lo comunicamos porque pensamos que no es útil.
13.- Colaboración con el equipo, preguntar si se entiende, si necesitan algo… esto hará que algunos bloqueos se eliminen y la comunicación mejore.
Lo que suele ocurrir: El desarrollador lo lee por ejemplo, y hay algo que no se entiende bien y en vez de preguntarte lo dejan ahí para más adelante… tampoco el resto del equipo vuelve a preguntar por estos bugs «bloqueados».
14.- Listado de bugs top 10 por resolver, como si fuera un backlog ordenado por prioridades sobre los bugs. Que el equipo los conozca para poder tomar conciencia de ellos y poder arreglarlos antes. Esto refuerza la revisión de las prioridades.
Lo que suele ocurrir: No se sabe cuales son esos bugs más prioritarios por resolver y para ir añadiendo al sprint en cuanto se pueda.

Ayudas y muletillas
Tener un bug de ejemplo o de plantilla para clonar o poder fijarse de toda la información relevante donde la estructura de la descripción por ejemplo ya esté informada.
Tener sistemas de alertas donde te avise de bugs sin tipo de error,… o que sea obligatorio el campo para poder darlo de alta. Alertas si la descripción está vacía… esto en Jira puede hacerse montando filtros y presentándolo en un dashboard de control.
Estudiar la evolución de bugs que el equipo soluciona contra los que van dándose de alta para ver esa gráfica y estimar a futuro qué tal los estamos tratando.
Hablar con los administradores de la herramienta donde se guarden los bugs ( Jira por ejemplo) por si nos pueden crear campos concretos en las tareas tipo bug ( como el tipo de error, componente, si tiene dependencia con automaticas,..) que se amolden a nuestras necesidades.
Hoy en día no pensar en la IA es echarse piedras en la cabeza, con un promt similar a este te ayudará a redactar con menos palabras , investiga y prueba a perfeccionarlo para tu caso.
«Actúa como un QA, crea un informe de error para un problema encontrado en la página de pedidos de pizza online en esta url xxxx en la versión de navegador yyy. Cuando hago click en el botón Enviar, la página no muestra el mensaje de éxito. El comportamiento esperado: Debería aparecer un mensaje de éxito cuando se han introducido todos los campos obligatorios del formulario.»
Conclusiones
Levantemos la mano si cualquier persona del equipo piensa que algo puede mejorarse del funcionamiento actual de los bugs, esas carencias, si se repiten, son las típicas que deben ser analizadas para evitarlas a futuro y cambiar en lo necesario el proceso. La calidad es responsabilidad de todos, y cuanto antes encontremos el problema menos costoso será el arreglo.
Son muchos los factores que intervienen a la hora de escribir un bug y puede parecer que nos quita mucho tiempo inicial, pero realmente un bug bien explicado y documentado facilita a desarrollo su entendimiento rápido y al tester que luego tiene que validarlo también si no eres tú mismo. Yo solo le veo ventajas y creo que es algo a revisar porque desde que lo damos de alta incluso a nosotros mismos se nos olvida y decimos… ¿cómo era? ¿qué hacía para que fallara?
La solución está en organizarse como equipo y pactar un contrato de mínimos sobre los bugs, y utilizar la IA para intentar ahorrar tiempo en su redacción.
Happy testing! Pues parecía sencillo pero después de leer todo esto ya no tanto no? Se puede trabajar en ello para mejorarlo en la medida de lo posible sin que nos quite mucho tiempo, ya sabemos, el tiempo es oro.
Un saludo y gracias por vuestro tiempo de lectura!!!
Y por favor, cualquier sugerencia o comentario, indícamelo, quiero aprender yo también de tí!!!
Hasta el próximo capítulo.