En este workshop daremos una introducción al uso de una potente herramienta para gestionar las versiones de distintos elementos de información usados para la construcción de proyectos de inteligencia artificial (IA), en concreto, de Machine Learning (ML). Estos elementos de información pueden ser datasets de entrenamiento y pruebas, parámetros de configuración de los algoritmos, modelos de ML, entre otros tipos de datos. Versionar todos estos elementos permiten recuperar la construcción de un modelo de ML en un momento especificado, lo cual es muy útil en operaciones de rollback, o en la aplicación de técnicas de transparencia analizando los datos de origen que generaron resultados previos a los del modelo vigente.
Contexto
MLOps son un conjunto de prácticas que en su conjunto permiten implementar el ciclo de vida de los proyectos de ML. Estas prácticas están organizadas en 3 fases: el diseño, el desarrollo del modelo y las operaciones.
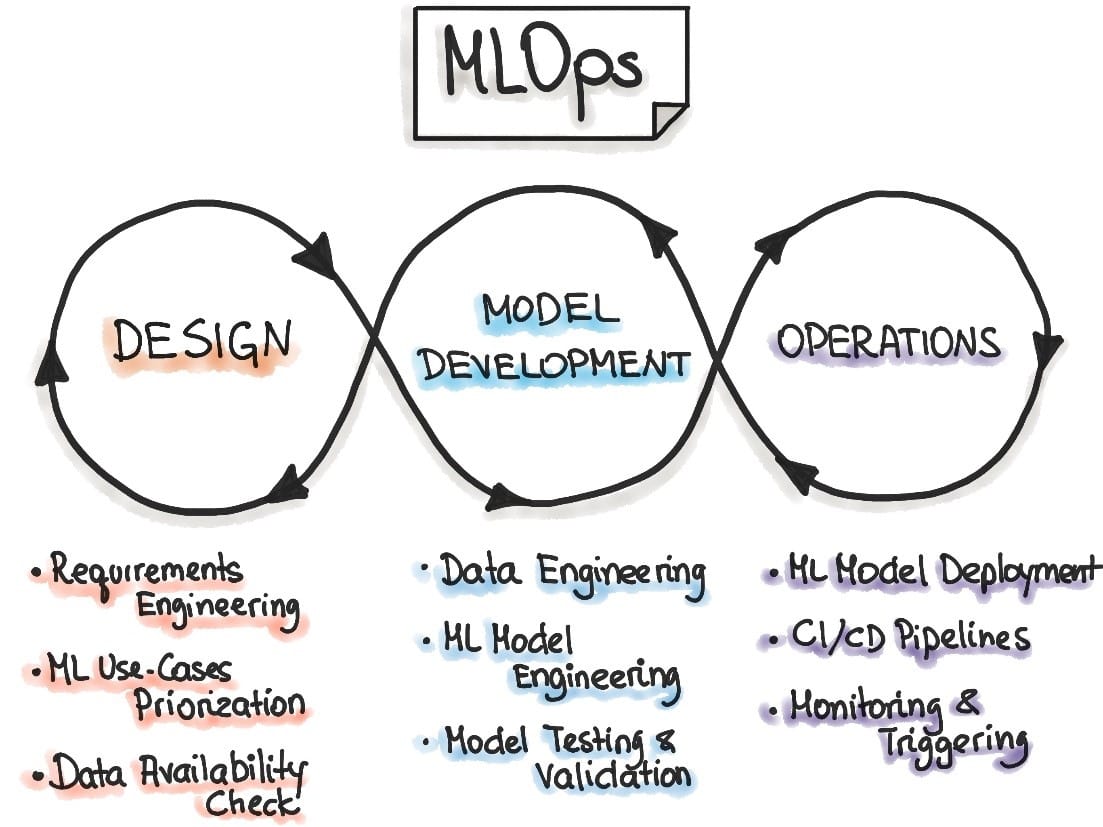
Diagrama 1: MLOps Principles
Los diferentes elementos de información entran en juego en las dos últimas fases del proceso MLOps, dónde los datos de entrenamiento, pruebas y validación son tratados a través de Data Engineering y los parámetros de los algoritmos son usados para el Model Engineering, y como resultado de la fase de desarrollo se obtiene uno o un conjunto de modelos de ML para será usados en la fase de operaciones. Si estos datos no son versionados no podrían recuperarse los modelos una vez construido y desplegados en una iteración del proceso.
Por tanto, se requiere una herramienta que permite registrar todos los cambios de datos que se han producido en cada una de las iteraciones, asociarlos entre sí y finalmente recuperarlos cuando se necesiten, es decir, que los modelos sean reproducibles. En el mercado existe variedad de herramientas que ofrecen esta solución a los ingenieros de MLOps, algunas son propietarias como Neptune o DagsHub, y otras son open-source como PachyDerm, LakeFS, entre otros. Aquí hablaremos de DVC que es una de las herramientas open-source de versionado de datos más usadas y mejor valoradas que existe hoy en día.
DVC (Data Version Control)
En su documentación oficial nos describe la herramienta de la siguiente manera:
DVC is a tool for data science that takes advantage of existing software engineering toolset. It helps machine learning teams manage large datasets, make projects reproducible, and collaborate better.
Aquí claramente nos explica cuáles son los objetivos principales de la herramienta, sin embargo, debemos profundizar en cómo usarla para conseguir dichos objetivos.
DVC hace uso de herramientas ya existentes para llevar a cabo el versionado de los datos. Se apoya en Git para enlazar el versionado del código con el versionado de los datos, además se puede integrar con múltiples proveedores remotos de almacenamiento, tanto clouds como on-premise para distribuir las versiones de los datos de manera colaborativa, al igual que lo hace git.
Una de las grandes ventajas que nos ofrece DVC, es que el modo de uso es muy similar a git, incluso usando comando iguales o similares, por lo que la velocidad de aprendizaje es rápida para aquellos que ya han usado git antes.
La forma de trabajar de DVC es versionar los elementos de datos en un repositorio distinto al del código, por tanto, los dataset, los parámetros y los modelos serán organizados en directorios distintos al código. Añadiremos cada uno de estos directorios a DVC quien creará un fichero de configuración con extensión dvc para cada directorio y que se versionará en el repositorio de git, los cuales permitirán enlazar la versión del código con la versión de cada directorio.
No existe un estándar establecido para definir los directorios de cada elemento de datos, pero se recomienda usar:
- data: para los datos de entrada, por ejemplo, los datasets.
- config: para las configuraciones y parámetros de la aplicación que crea los modelos.
- models: para los modelos construidos.
Es importante resaltar que debemos incluir estos directorios en el fichero .gitignore para prevenir subidas de los mismos al repositorio de git.
Instalación
DVC se puede instalar sobre los principales sistemas operativos (MacOs, Windows o Linux), y su instalación en cada uno de ellos suele ser sencilla. En resumen, al basarse en un paquete de Python puede ser instalado fácilmente con pip o conda. Importante tener en cuenta que, aunque se apoye en git, no esta incluido dentro del paquete de instalación por lo que se requiere instalar también git.
$ pip install dvc dvc-s3Nota: dvc-s3 es el paquete requerido para conectarse a los buckets de AWS S3
Proyecto de ML de demostración
Para mostrar el uso de DVC de forma más práctica, nos basaremos en un ejemplo sencillo subido a kaggle llamado Student Performance Prediction | 91% que hace uso del dataset de entrada Students Performance Dataset.
Para trabajar sobre este ejemplo, clona o descarga el siguiente proyecto:
$ git clone https://github.com/jhmz333/demo-dvc.git
# Nota: al clonar este repositorio, posteriormente debes apuntar a un repositorio remoto propio para subir tus cambios.El contenido de este repositorio contiene los recursos mínimos necesarios para la demostración, entre ellos, recursos propios de un proyecto Python versionado con git, y los recursos de DVC (.dvc, .dvcignore, config.dvc, data.dvc, models.dvc).
Si has descargado el proyecto como un zip, deberás iniciar el proyecto con git (esto no es necesario si lo has clonado):
$ git initAntes de comenzar a trabajar con DVC, debemos crear los directorios para almacenar los datos, configuraciones y modelos como comentados antes y añadir sus respectivos ficheros.
También deberás iniciar el repositorio local de DVC, donde se creará el directorio .dvc que usa para su gestión, y que se versionará en el repositorio de código de git.
$ dvc initA continuación instalamos las dependencias de Python que son necesarias para ejecutar el notebook src/student-performance-prediction-91.ipynb que procesa los datos:
$ pip install -r requeriments.txtProveedor de almacenamiento
Es importante establecer dónde se alojarán los datos para su correcta distribución, y DVC permite conectar con los principales proveedores de la nube como también las principales herramientas on-premises de gestión de almacenamiento, aquí se explica mejor cada una de ellas.
En este workshop mostramos el uso de un bucket de AWS S3 para almacenar las versiones de los datos que iremos modificando. Para ello, es necesario tener instalado aws-cli en nuestro equipo y tener configurado un perfil con sus credenciales y permisos para acceder al bucket donde almacenaremos las versiones, una vez configurado podemos añadir el repositorio remoto a la configuración de dvc con el siguiente comando:
$ dvc remote add dvc-demo s3://{name_of_bucket}/{path_of_folder}Con esto, ya tenemos la integración con el sitio donde almacenaremos las versiones de los elementos de datos.
Versionando datos
En el trabajo diario de los científicos de datos se generan experimentos que por diferentes motivos se requieren versionar. Como hemos visto antes el código y los datos deben versionarse de forma separada, por tanto, requiere una coordinación entre los comandos que usamos de git y de DVC. Hasta ahora ya hemos preparado el proyecto para que pueda trabajar con sus repositorios remotos.
A continuación, añadimos a DVC los directorios data, config y models y subiremos al bucket de S3 una primera versión.
$ dvc add data config models
$ dvc pushDespués de ejecutar el comando dvc add veremos que se crearán los ficheros data.dvc, models.dvc y config.dvc. Posteriormente subiremos al repositorio de git los recursos del código junto con los ficheros que ha generado DVC.
Una vez finalizada la subida se crearán las siguientes carpetas en el bucket de S3; el primer nivel corresponde a cada uno de los hash md5 que se generan por cada versión de cada elemento de datos.
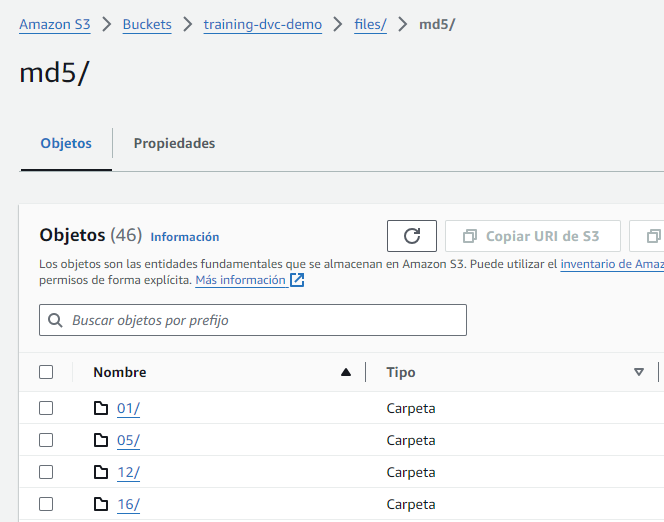
Si entramos en alguna carpeta de ellas, se muestran los ficheros que corresponden con esta versión. Es importante destacar que DVC, al igual que git, solo guarda los cambios entre la versión anterior y la nueva, por lo que hace un uso optimo del espacio de almacenamiento de las versiones.
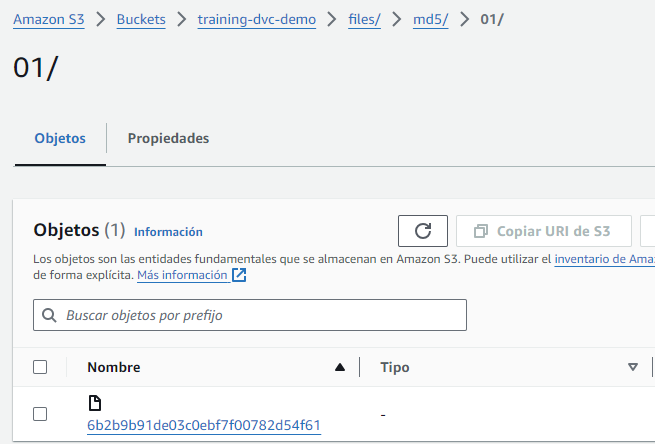
Finalmente podemos enlazar las versiones generadas por DVC subiendo al repositorio git los ficheros .dvc
$ git add .
$ git commit -m "Linking the code with the data items"
$ git pushVersionar nuevos experimentos
Cuando cambiamos el código o los elementos de datos podemos decir que se genera un nuevo experimento y muchas veces necesitamos versionarlo para recuperarlo en el futuro, sobre todo cuando llega a entornos productivos. Para generar una nueva versión es suficiente con ejecutar de nuevo los comandos que hemos visto en esta sesión.
$ dvc add data config models
$ dvc push
$ git add .
$ git commit -m "New version of experiment"
$ git pushRecuperar un experimento
Una vez que se han versionado múltiples experimentos, puedes recuperar cualquiera de ellos a partir de las revisiones de git, es decir, primero debemos recuperar la versión que necesitamos del repositorio de git haciendo uso de su comando checkout, con ello descargaremos solo los recursos del código, y posteriormente descargaremos los elementos de datos con DVC haciendo uso de su comando pull.
$ git checkout {git_revision}
$ dvc pullConclusiones
En MLOps siempre ha sido un reto recuperar una versión de un experimento previo con el objetivo de reproducir un modelo de ML concreto generado en un momento determinado, ya que las herramientas de versionado de código como git, no son adecuadas para gestionar documentos de gran tamaño. DVC ha nacido para cubrir esta necesidad, y lo más importante es que tiene mucha similitud con git, por lo que podemos trabajar de manera más cómoda y rápida. Es importante destacar que DVC puede usarse también para versionar solo los datos sin necesidad de enlazarlos con recurso de código, por lo que sus casos de uso se extienden fuera del mundo MLOps.
En este workshop hemos mostrado una introducción del uso de DVC para integrar el versionado de datos con el versionado del código en proyectos de ML, pero DVC también ofrece más herramientas útiles cómo por ejemplo, Data pipelines, Experiment Management, Model registry, entre otros, para complementar otros procesos importante de MLOps.